正则表达式
基于Python正则表达式提取搜索结果中的站点地址
发布时间:2022-04-16 发布网站:脚本宝典
脚本宝典收集整理的这篇文章主要介绍了基于Python正则表达式提取搜索结果中的站点地址,脚本宝典觉得挺不错的,现在分享给大家,也给大家做个参考。
正则表达式对于Python来说并不是独有的,最近在把@R_512_1001@搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址。
这其中涉及几个需要解决的问题:
1、获取搜索的结果文本
为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果。
获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本
2、分析如何提取站点信息
首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息。
我使用IE8自带的开发工具(按F12就会弹出来)中的探查器功能查看自己要关心的内容有什么特殊的格式
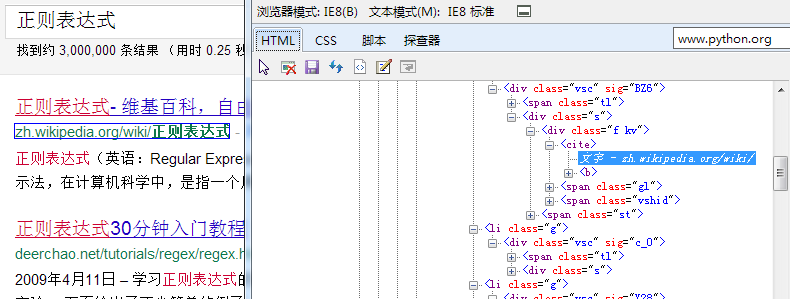
从上图可以看出我需要的站点在标签<cITe></cite>中,所以我使用正则表达式提取这其中的文本是否就可以呢?
3、编写正则表达式来获取站点地址
接下来的就是写表达式了,我使用Python3.2编写的,方便好用(~_~)
代码如下,先把搜索结果页面保持到e:/t3.txt中,在执行如下代码
import re p = re.COMpile(r'<cite>([^<>\/].+?)</cite>') f = oPEn("e:/t3.txt", encoding='utf-8') content = f.read() PRint ("\n".join(p.findall(content)))
运行如下:
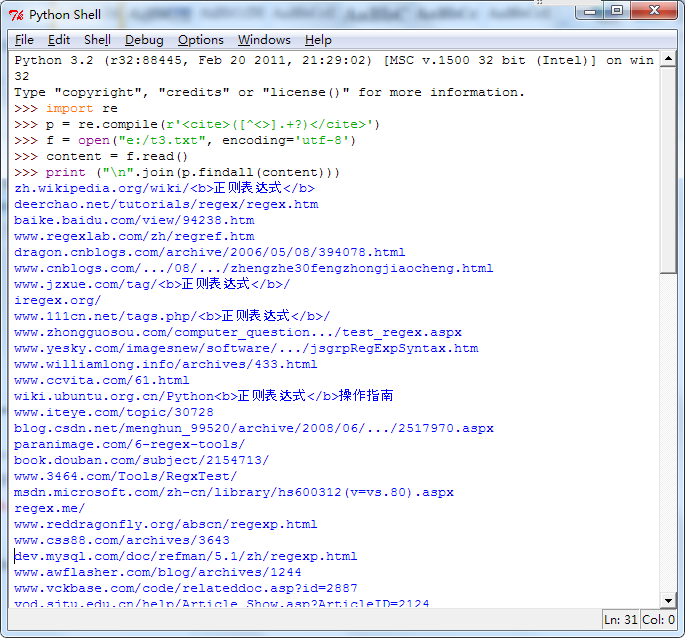
大家可以对照一下运行效果图,看看所有的站点地址是不是都给获取到了。
您可能感兴趣的文章:
脚本宝典总结
以上是脚本宝典为你收集整理的基于Python正则表达式提取搜索结果中的站点地址全部内容,希望文章能够帮你解决基于Python正则表达式提取搜索结果中的站点地址所遇到的问题。
本图文内容来源于网友网络收集整理提供,作为学习参考使用,版权属于原作者。
如您有任何意见或建议可联系处理。小编QQ:384754419,请注明来意。
猜你在找的正则表达式相关文章
- 去除内容中的html 2022-04-16
- Python正则表达式保姆式教学详细教程 2022-04-16
- 十分钟上手正则表达式 上篇 2022-04-16
- 十分钟上手正则表达式 下篇 2022-04-16
- 深入浅出正则表达式中的边界\b和\B 2022-04-16
- 轻松入门正则表达式之非贪婪匹配篇详解 2022-04-16
- 轻松掌握正则表达式findall函数详解 2022-04-16
- 正则表达式用法详解 2022-04-16
- 36个正则表达式(开发效率提高80%) 2022-04-16
- Python正则表达式指南 推荐 2022-04-16
全站导航更多
html5HTML/XhtmlCSSXML/XSLTDreamweaver教程Frontpage教程心得技巧JavaScriptASP.NETPHP编程正则表达式AJAX相关ASP编程JSP编程编程10000问CSS/HTMLFlexvbsDOS/BAThtahtcpythonperl游戏相关VBA远程脚本ColdFusionMsSqlMysqlmariadboracleDB2mssql2008mssql2005SQLitePostgreSQLMongoDB星外虚拟主机华众虚拟主机Linuxwin服务器FTP服务器DNS服务器Tomcatnginxzabbix云和虚拟化bios系统安装系统系统进程Windows系列LINUXRedHat/CentosUbuntu/DebianFedoraSolaris红旗Linux建站经验微信营销网站优化网站策划网络赚钱网络创业站长故事alexa域名photoshop教程摄影教程Fireworks教程CorelDraw教程Illustrator教程Painter教程Freehand教程IndesignSketch笔记本主板内存CPU存储显卡显示器光存储鼠标键盘平板电脑安全教程杀毒防毒安全设置病毒查杀脚本攻防入侵防御工具使用业界动态Exploit漏洞分析
最新正则表达式教程