Mysql
mysql过滤复制思路详解
发布时间:2022-04-18 发布网站:脚本宝典
脚本宝典收集整理的这篇文章主要介绍了mysql过滤复制思路详解,脚本宝典觉得挺不错的,现在分享给大家,也给大家做个参考。
MySQL过滤复制
@H_360_18@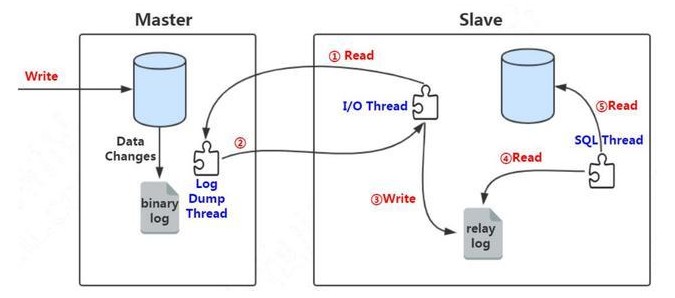
两种思路:
所以主从过滤复制尽量不用,要用的也仅仅在从库上使用,因为要尽可能保证binlog的完整性
主库上实现
在Master 端为保证二进制日志的完整, 不使用二进制日志过滤。
主库配置参数:
#配置文件中添加 binlog-do-db=db_name #定义白名单,仅将制定数据库的相关操作记入二进制日志。如果主数据库崩溃,那么仅仅之恢复指定数据库的内容,不建议在主服务器端使用,这样导致日志不完整。 binlog-ignore-db=db_name #定义黑名单, 定义ignore 的库上发生的写操作将不会记录到二进制日志中
从库上实现
可以下载配置文件中
REPLICATE_DO_DB = (db_list) #过滤复制哪些库 REPLICATE_IGNORE_DB = (db_list) #不复制哪些库 REPLICATE_DO_TABLE = (tbl_list) #过滤表 REPLICATE_IGNORE_TABLE = (tbl_list) #忽略过滤表 REPLICATE_WILD_DO_TABLE = (wild_tbl_list) #根据正则匹配过滤表 REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) #根据正则匹配忽略过滤这些表 REPLICATE_REWRITE_DB = (db_pair_list) #将源数据库的db1发生的语句重写到从库的db2 CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB = ((db1, db2));
语法:
官网语法参考:https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html
CHANGE REPLICATION FILTER filter[, filter][, ...] filter: { REPLICATE_DO_DB = (db_list) | REPLICATE_IGNORE_DB = (db_list) | REPLICATE_DO_TABLE = (tbl_list) | REPLICATE_IGNORE_TABLE = (tbl_list) | REPLICATE_WILD_DO_TABLE = (wild_tbl_list) | REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) | REPLICATE_REWRITE_DB = (db_pair_list) }
#从库实现过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(db); start slave sql_thread; #取消过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(); start slave sql_thread;
一些问题
主库删除某个表,从库没有这个表,导致从库sql线程关闭
或者主从正常,从库不小心删除某个表,主库随后再删除这个表,从库又会去删除这个不存在的表,报错,导致sql线程退出
解决方法:跳过这一步操作
解决方案:从库sql线程跳过误操作的步骤 stop slave sql_thread; #找到Executed_Gtid_Set执行到19 set gtid_next='94fc1fbe-b7a0-11eb-b0a0-000c2969aba1:20'; 将gtid分配给下一个事务 begin;commit; set gtid_next=automatic; 系统自动分配gtid start slave sql_thread;
到此这篇关于mysql过滤复制思路详解的文章就介绍到这了,更多相关mysql过滤复制 内容请搜索脚本宝典以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本宝典!
您可能感兴趣的文章:
脚本宝典总结
以上是脚本宝典为你收集整理的mysql过滤复制思路详解全部内容,希望文章能够帮你解决mysql过滤复制思路详解所遇到的问题。
本图文内容来源于网友网络收集整理提供,作为学习参考使用,版权属于原作者。
如您有任何意见或建议可联系处理。小编QQ:384754419,请注明来意。
猜你在找的Mysql相关文章
- mysql主从同步是什么 2022-05-31
- 详解mysql触发器trigger实例 2022-04-18
- 详解MySQL存储过程的创建和调用 2022-04-18
- 详解Mysql中tinyint与int的区别 2022-04-18
- Mysql的复合索引如何生效 2022-04-18
- mysql+mybatis实现存储过程+事务 + 多并发流水号获取 2022-04-18
- SQL查询至少连续七天下单的用户 2022-04-18
- SQL查询至少连续n天登录的用户 2022-04-18
- MySQL数据库终端—常用操作指令代码 2022-04-18
- 详解MySQL如何有效的存储IP地址及字符串IP和数值之间如何转换 2022-04-18
全站导航更多
html5HTML/XhtmlCSSXML/XSLTDreamweaver教程Frontpage教程心得技巧JavaScriptASP.NETPHP编程正则表达式AJAX相关ASP编程JSP编程编程10000问CSS/HTMLFlexvbsDOS/BAThtahtcpythonperl游戏相关VBA远程脚本ColdFusionMsSqlMysqlmariadboracleDB2mssql2008mssql2005SQLitePostgreSQLMongoDB星外虚拟主机华众虚拟主机Linuxwin服务器FTP服务器DNS服务器Tomcatnginxzabbix云和虚拟化bios系统安装系统系统进程Windows系列LINUXRedHat/CentosUbuntu/DebianFedoraSolaris红旗Linux建站经验微信营销网站优化网站策划网络赚钱网络创业站长故事alexa域名photoshop教程摄影教程Fireworks教程CorelDraw教程Illustrator教程Painter教程Freehand教程IndesignSketch笔记本主板内存CPU存储显卡显示器光存储鼠标键盘平板电脑安全教程杀毒防毒安全设置病毒查杀脚本攻防入侵防御工具使用业界动态Exploit漏洞分析
最新Mysql教程