Python实现CART决策树算法及详细注释
脚本宝典收集整理的这篇文章主要介绍了Python实现CART决策树算法及详细注释,脚本宝典觉得挺不错的,现在分享给大家,也给大家做个参考。
一、CART决策树算法简介
CART(Classification And Regression Trees 分类回归树)算法是一种树构建算法,既可以用于分类任务,又可以用于回归。相比于 ID3 和 C4.5 只能用于离散型数据且只能用于分类任务,CART 算法的适用面要广得多,既可用于离散型数据,又可以处理连续型数据,并且分类和回归任务都能处理。
本文仅讨论基本的CART分类决策树构建,不讨论回归树和剪枝等问题。
首先,我们要明确以下几点:
1. CART算法是二分类常用的方法,由CART算法生成的决策树是二叉树,而 ID3 以及 C4.5 算法生成的决策树是多叉树,从运行效率角度考虑,二叉树模型会比多叉树运算效率高。
2. CART算法通过基尼(gini)指数来选择最优特征。
二、基尼系数
基尼系数代表模型的不纯度,基尼系数越小,则不纯度越低,注意这和 C4.5的信息增益比的定义恰好相反。
分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼系数定义为:
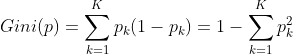
若CART用于二类分类问题(不是只能用于二分类),那么概率分布的基尼系数可简化为
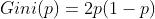
假设使用特征 A 将数据集 D 划分为两部分 D1 和 D2,此时按照特征 A 划分的数据集的基尼系数为:
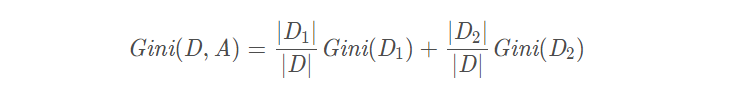
三、CART决策树生成算法
输入:训练数据集D,停止计算的条件
输出:CART决策树
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
(1)计算现有特征对该数据集的基尼指数,如上面所示;
(2)选择基尼指数最小的值对应的特征为最优特征,对应的切分点为最优切分点(若最小值对应的特征或切分点有多个,随便取一个即可);
(3)按照最优特征和最优切分点,从现结点生成两个子结点,将训练数据集中的数据按特征和属性分配到两个子结点中;
(4)对两个子结点递归地调用(1)(2)(3),直至满足停止条件。
(5)生成CART树。
算法停止的条件:结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类,如完全属于同一类则为0),或者特征集为空。
注:最优切分点是将当前样本下分为两类(因为我们要构造二叉树)的必要条件。对于离散的情况,最优切分点是当前最优特征的某个取值;对于连续的情况,最优切分点可以是某个具体的数值。具体应用时需要遍历所有可能的最优切分点取值去找到我们需要的最优切分点。
四、CART算法的Python实现
若是二分类问题,则函数calcGini和choose_best_feature可简化如下:
# 计算样本属于第1个类的概率p def calcPRobabilITyEnt(dataset): numEntries = len(dataset) count = 0 label = dataset[0][len(dataset[0]) - 1] for example in dataset: if example[-1] == label: count += 1 probabilityEnt = float(count) / numEntries return probabilityEnt def choose_best_feature(dataset): # 特征总数 numFeatures = len(dataset[0]) - 1 # 当只有一个特征时 if numFeatures == 1: return 0 # 初始化最佳基尼系数 bestGini = 1 # 初始化最优特征 index_of_best_feature = -1 for i in range(numFeatures): # 去重,每个属性值唯一 uniqueVals = set(example[i] for example in dataset) # 定义特征的值的基尼系数 Gini = {} for value in uniqueVals: sub_dataset1, sub_dataset2 = split_dataset(dataset,i,value) prob1 = len(sub_dataset1) / float(len(dataset)) prob2 = len(sub_dataset2) / float(len(dataset)) probabilityEnt1 = calcProbabilityEnt(sub_dataset1) probabilityEnt2 = calcProbabilityEnt(sub_dataset2) Gini[value] = prob1 * 2 * probabilityEnt1 * (1 - probabilityEnt1) + prob2 * 2 * probabilityEnt2 * (1 - probabilityEnt2) if Gini[value] < bestGini: bestGini = Gini[value] index_of_best_feature = i best_split_point = value return index_of_best_feature, best_split_point
五、运行结果

到此这篇关于Python实现CART决策树算法及详细注释的文章就介绍到这了,更多相关Python策树算法内容请搜索脚本宝典以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本宝典!
脚本宝典总结
以上是脚本宝典为你收集整理的Python实现CART决策树算法及详细注释全部内容,希望文章能够帮你解决Python实现CART决策树算法及详细注释所遇到的问题。
本图文内容来源于网友网络收集整理提供,作为学习参考使用,版权属于原作者。
如您有任何意见或建议可联系处理。小编QQ:384754419,请注明来意。
- python怎么读excel 2022-05-15
- Python Pygame实战之打地鼠小游戏 2022-04-17
- Django admin实现TextField字段changelist页面换行、空格正常显示 2022-04-17
- 基于Python实现的恋爱对话小程序详解 2022-04-17
- 分享6 个值得收藏的 Python 代码 2022-04-17
- python+appium实现自动化测试的示例代码 2022-04-17
- Python实现带GUI界面的手写数字识别 2022-04-17
- Python类的继承与多态详细介绍 2022-04-17
- Python实战之MNIST手写数字识别详解 2022-04-17
- Python实现自动玩贪吃蛇程序 2022-04-17